HPCクラスター構築(その6)
1台のコンピュータではプログラムの実行速度が遅い場合、複数台のコンピュータを使って、実行速度を速くできます。そのために使われる標準的な方法がMPI(Message Passing Interface)です。ライブラリとコンパイラのラッパー、起動用のコマンドなどのセットになっていて、Ubuntuを使っていれば、簡単にインストールできます。プログラムはMPI用に書き換える必要があります。ここでは、MPIのインストールと、MPI用姫野ベンチをダウンロードしてMPI用にコンパイルしてhpc01単独、hpc01とhpc02の2台で実行の比較を行います。
openMPIのインストール
hpc01とhpc02で
sudo apt install openmpi-bin
を実行します。
姫野ベンチのインストール
理研のホームページから姫野ベンチのFortran MPI用のソースコードをダウンロードします。
ファイル名はhimenobmtxpr.f90になります。
/home/hpc/himenoに入れます。
姫野ベンチのソースコードをコンパイル
Fortran f90 のMPI用コンパイラであるmpif90で姫のベンチのソースコードをコンパイルして、実行可能なファイルを作成します。
mpif90 -O3 himenobmtxpr.f90 -o himeno
hpc01のコア数を調べる
全コアを使ってMPIプログラムを実行するために、hpc01のコア数を調べます。
nprocコマンドで4コアであることがわかります。
hpc01で4コアを使って姫野ベンチを実行する
mpiプログラムを実行するためのコマンドがmpirunです。
mpirun -np 4 ./himeno
で実行します。-np 4オプションで4コアでの実行を指示します。
姫野ベンチを実行すると最初にグリッドサイズを聞かれますので、最大サイズのxlを入力します。xlは1024x512x512になります。
続いてグリッドを各方向に何分割するかを聞かれます。ここでは1 4 1を入力します。いろいろな分割の可能性がありますが、分割の仕方によって、表示される性能が変化しますので、興味がある方は試してみてください。
入力が終わると3サイクルのリハーサルシミュレーションが行われ、性能が表示されます。この実行時間を元にして、約1分間で実行可能なサイクル数が計算され、そのサイクル数だけ本番のシミュレーションが行われます。したがって、姫野ベンチはコンピュータの性能に関わらず、常に約1分で実行が終わります。
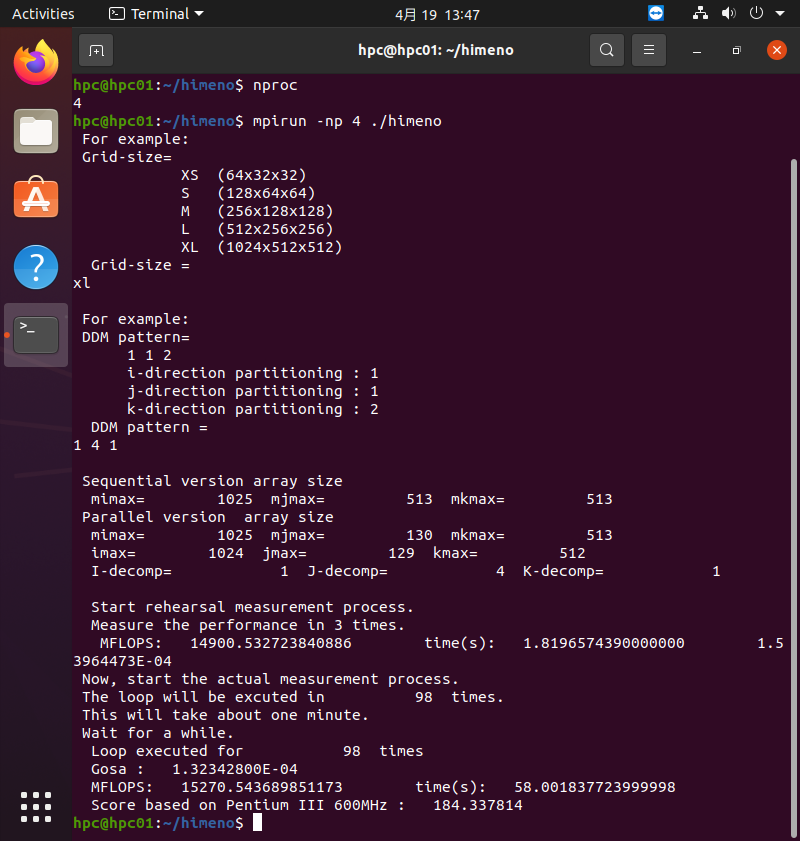
結果はhpc011台では約15GFLOPSになりました。
hpc01とhpc02で合計8コアを使って姫野ベンチを実行する
hpc01上でmpirun -np 4 ./himenoとすると、4つのコアはhpc01のコアが使われました。mpirun -np 8 ./himenoとすると、下記のエラーになります。
There are not enough slots available in the system to satisfy the 8
slots that were requested by the application:
./himeno
slotsとはコアのことです。4コアしかないのに8コア使おうとしたので当然の結果です。2ノード(host)以上使ってmpiプログラムを実行する場合、実行するホスト名が記述されたhostfileが必要になります。hostfileにはhost名と各ホストに何コアあるかをslots=の後に記述します。ここではmpihostsに記述しました。
hpc@hpc01:~/himeno$ cat mpihosts
hpc01 slots=4
hpc02 slots=4
hpc@hpc01:~/himeno$
これを使ってhpc01とhpc02で8コアで実行するには
mpirun -np 8 --hostfile mpihosts ./himenoを実行します。
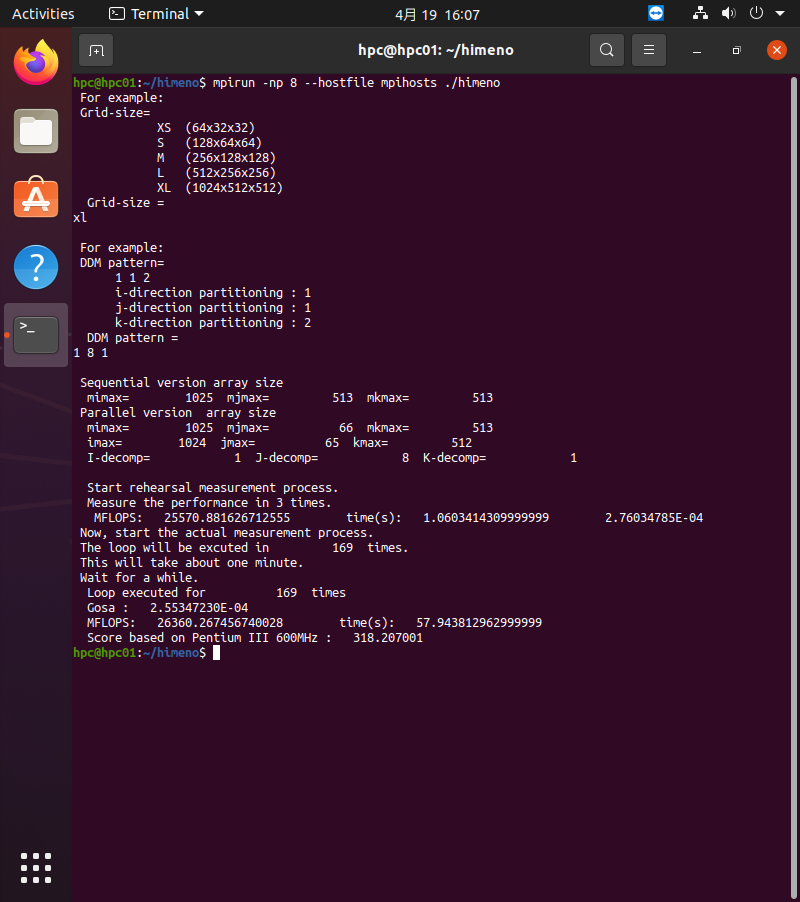
約26GFLOPSの結果でした。並列性能はイマイチのような気がしますが、リアルマシンではないので、機能のみに注目することにしましょう。機能的に問題なければ、System Cloner for Linux by Server Gearを使って、実マシンにcloneすれば本来の性能を調べることができますので。