HPCクラスター構築(その9)
MPIプログラムを複数ノードを使って実行させる場合、hostfileの作成や、またどのノードが何コア空いているかを調べたりするのに、手間と時間がかかり、思いついてパッと実行することができません。しかし、ジョブスケジューラを使えば、準備やチェックが全く不要で、直ぐにジョブの投入が可能です。今回は姫野ベンチのMPIバージョンを、lavaに投入する方法の実際を解説していきます。
姫野ベンチをopenMPIで実行する方法はこちらをご覧ください。
hpc01にhpcでログインし、上記で作成した/home/hpc/himenoに移動します。
姫野ベンチを実行する場合、グリッドサイズと、グリッドの分割方法を入力する必要があります。このままだと、bsubでジョブ投入する際にうまく投入できません。そこでコマンドラインのみで姫野ベンチを実行できるようrun_himenoというshell scriptを作ります。./run_himeno 実行コア数のように使えるようにします。run_himenoは次のようなスクリプトです。
hpc@hpc01:~/himeno$ cat run_himeno
#!/bin/bash
mpirun -np $1 ./himenop $1
この中でhimenopというスクリプトを呼び出していますがそれは次のようになっています。
hpc@hpc01:~/himeno$ cat himenop
#!/bin/bash
./himeno <<.
xl
1 $1 1
.
hpc@hpc01:~/himeno$
動作を試してみましょう。
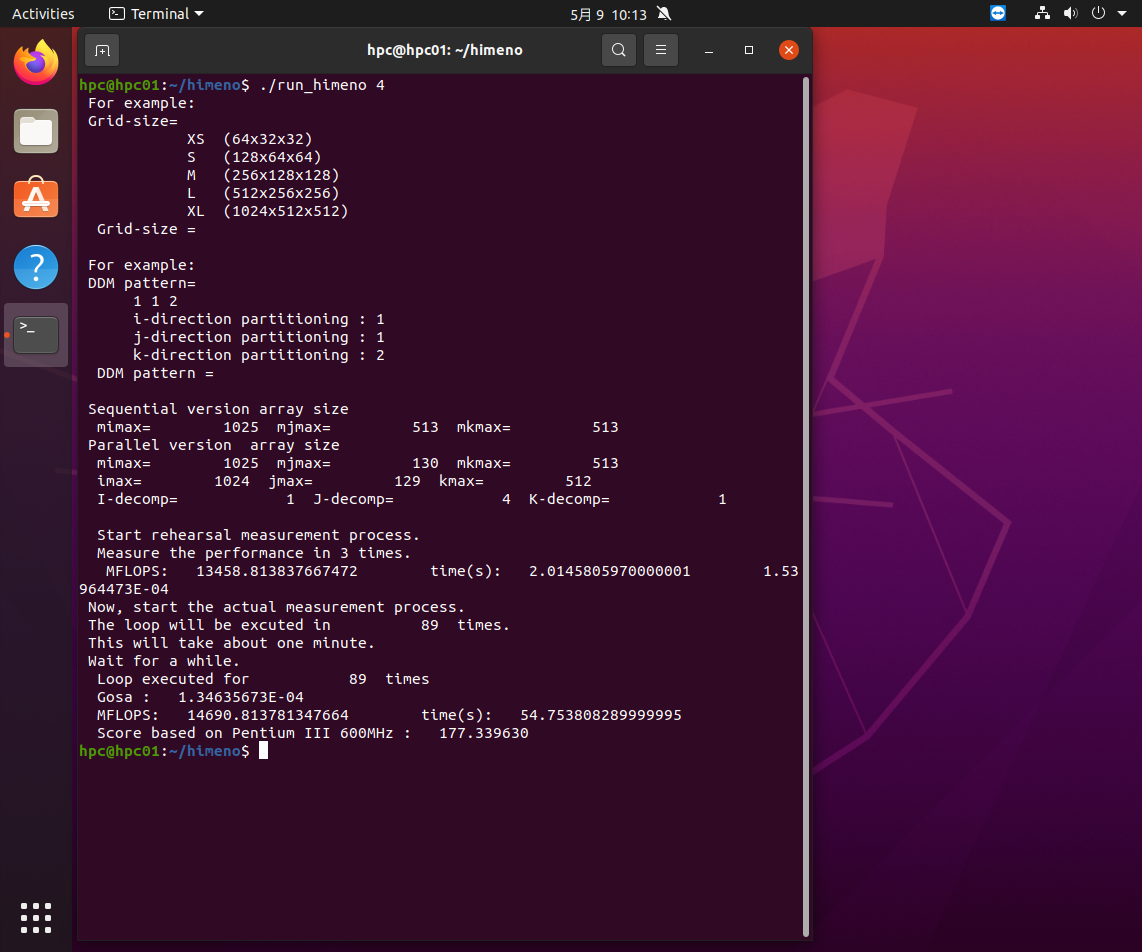
Grid-sizeにxlが選択され1 4 1に分割されているのがわかります。実行速度も妥当です。
script:run_himenoの中でmpirunを実行していますが、bsubでMPIジョブを投入する際にはmpirunの代わりにopenmpi-mpirunを使います。mpirunで複数ノードで実行する場合、hostfileを渡す必要がありますが、hostfileの内容がどうなるのかは、bsubでないとわかりません。bsubからopenmpi-mpirunが呼ばれると、bsubがセットする実行ノードやコア数の環境変数を調べてopenmpi-mpirunがhostfileを作って、mpirunを呼び出し渡してくれます。以上の理由から、姫野ベンチをbsubで投入するbsub_himenoは以下のようなスクリプトになります。
hpc@hpc01:~/himeno$ cat bsub_himeno
#!/bin/bash
bsub -n $1 -o logdir openmpi-mpirun ./himenop $1
hpc@hpc01:~/himeno$
4コアで実行してみましょう。実行する前に実行結果を入れるlogdirを作成します。
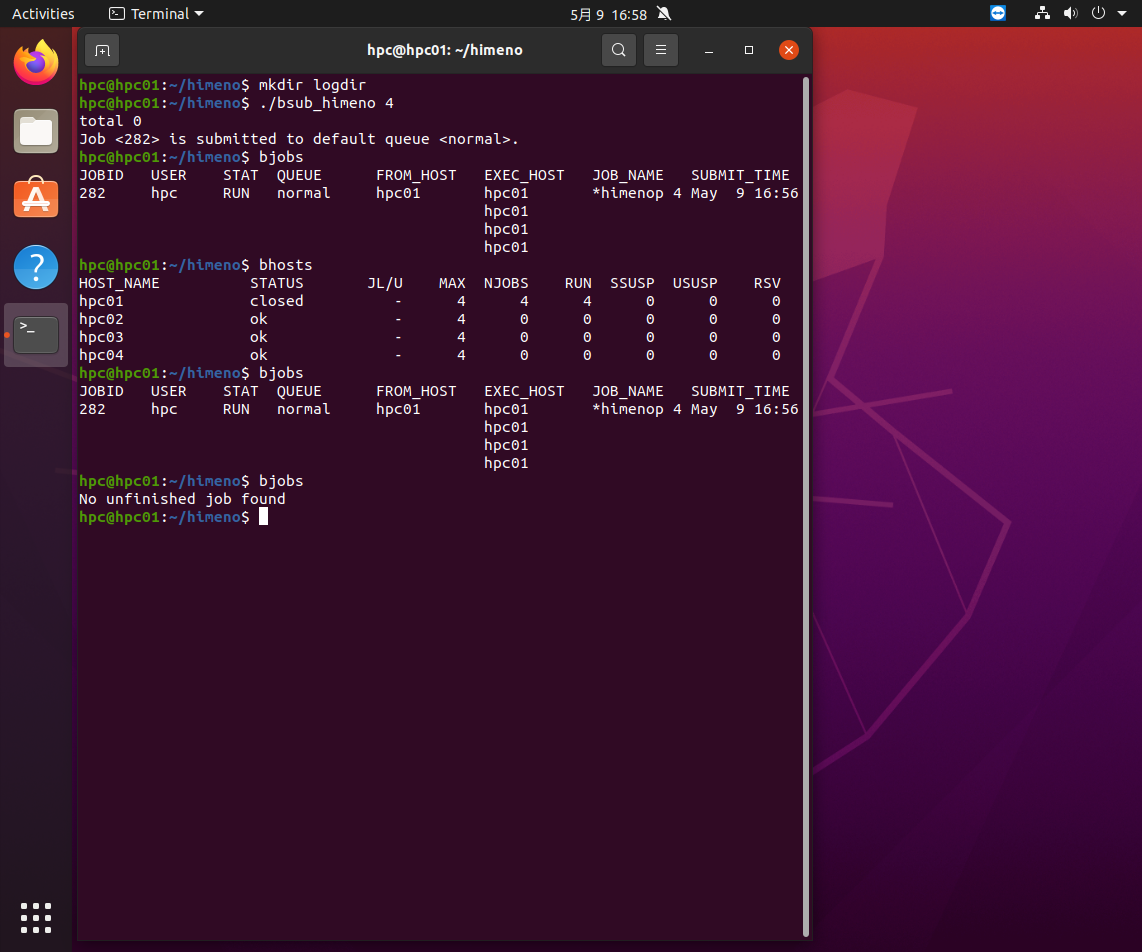
bsub_himeno 4でジョブが投入され、bjobsで見るとhpc01の4コアで実行されいるのがわかります。bhostsで見ると、hpc01のMAXが4、NJOBSが4、RUNが4になって全コアが使われているため、hpc01はclosedの状態になっています。その後しばらくするとジョブが終了します。
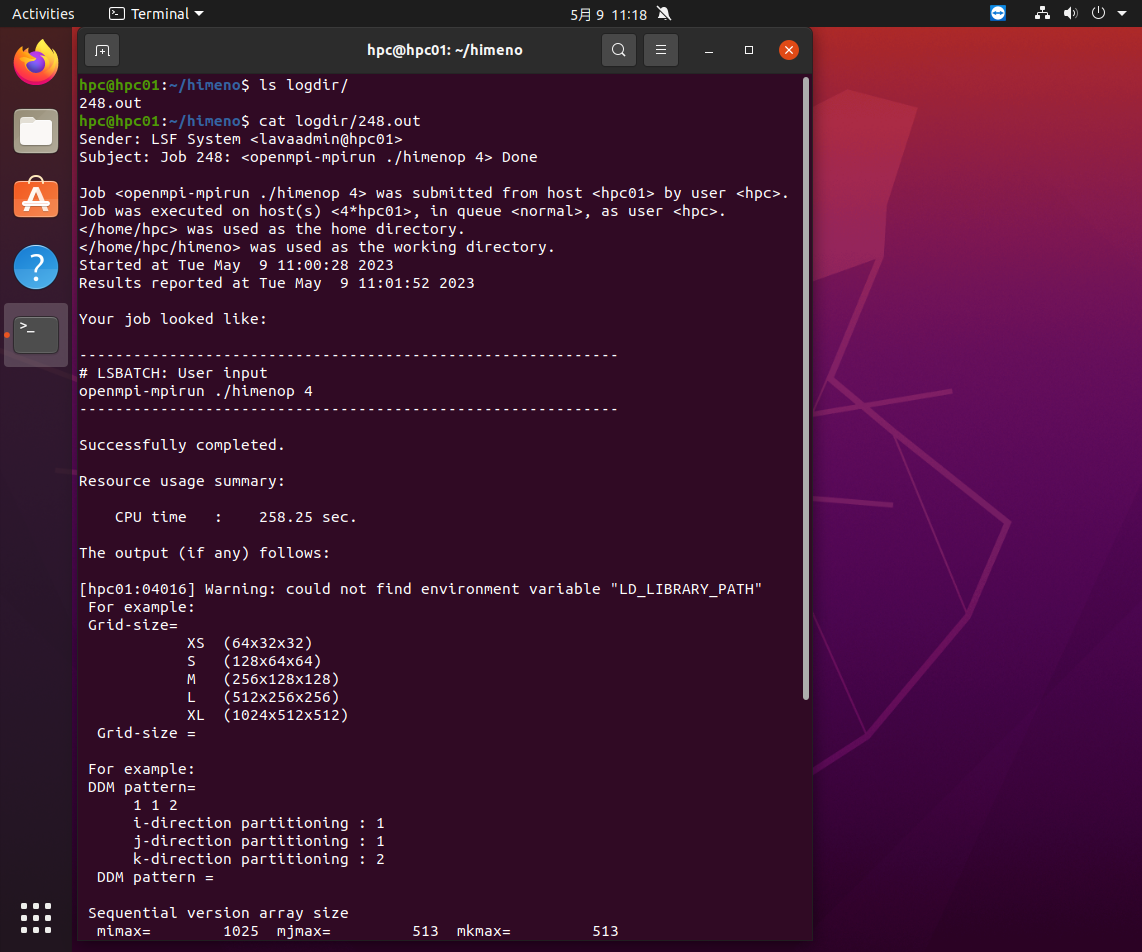
実行結果はlogdirの下にあります。結果を見てみると、問題なく実行できていることがわかります。
それでは締めくくりとして、姫野ベンチのMPIバージョンを2,4,8,16プロセスで実行するジョブを連続投入して、実行状態を観察してみましょう。ちなみに、姫野ベンチにはopenMPバージョンもありますが、MPIバージョンとの違いは、1ノード内でしか並列計算ができない点にあります。複数ノードでの並列計算が必要な場合は、MPIを使う必要があります。
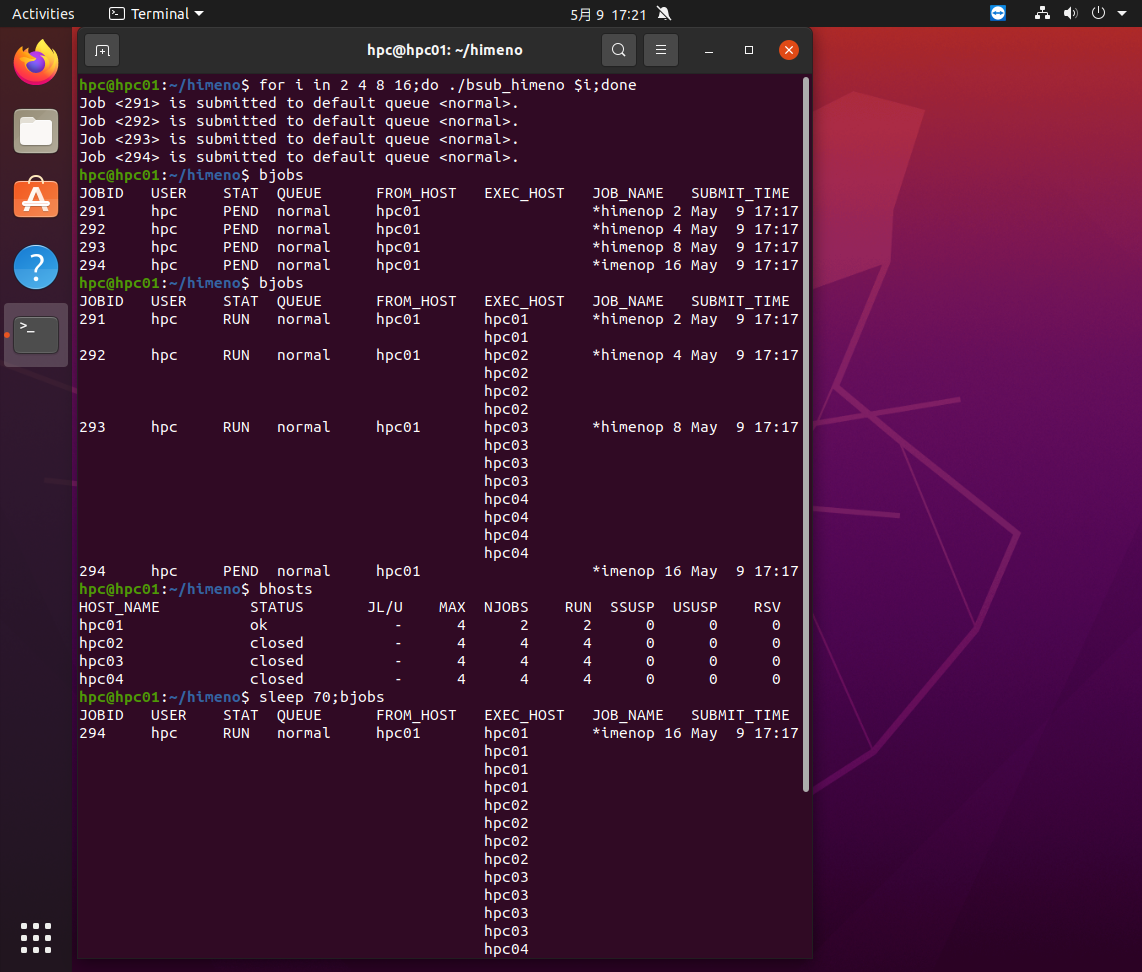
bjobsで見ると、2プロセスのジョブがhpc01で、4プロセスのジョブがhpc02で、8プロセスのジョブがhpc03とhpc04を使って実行しているのがわかります。bhostsで見るとhpc01のみ2プロセス分の空きがありますが、ほかのノードは全部使われているので、16プロセスのジョブはPendingになっています。
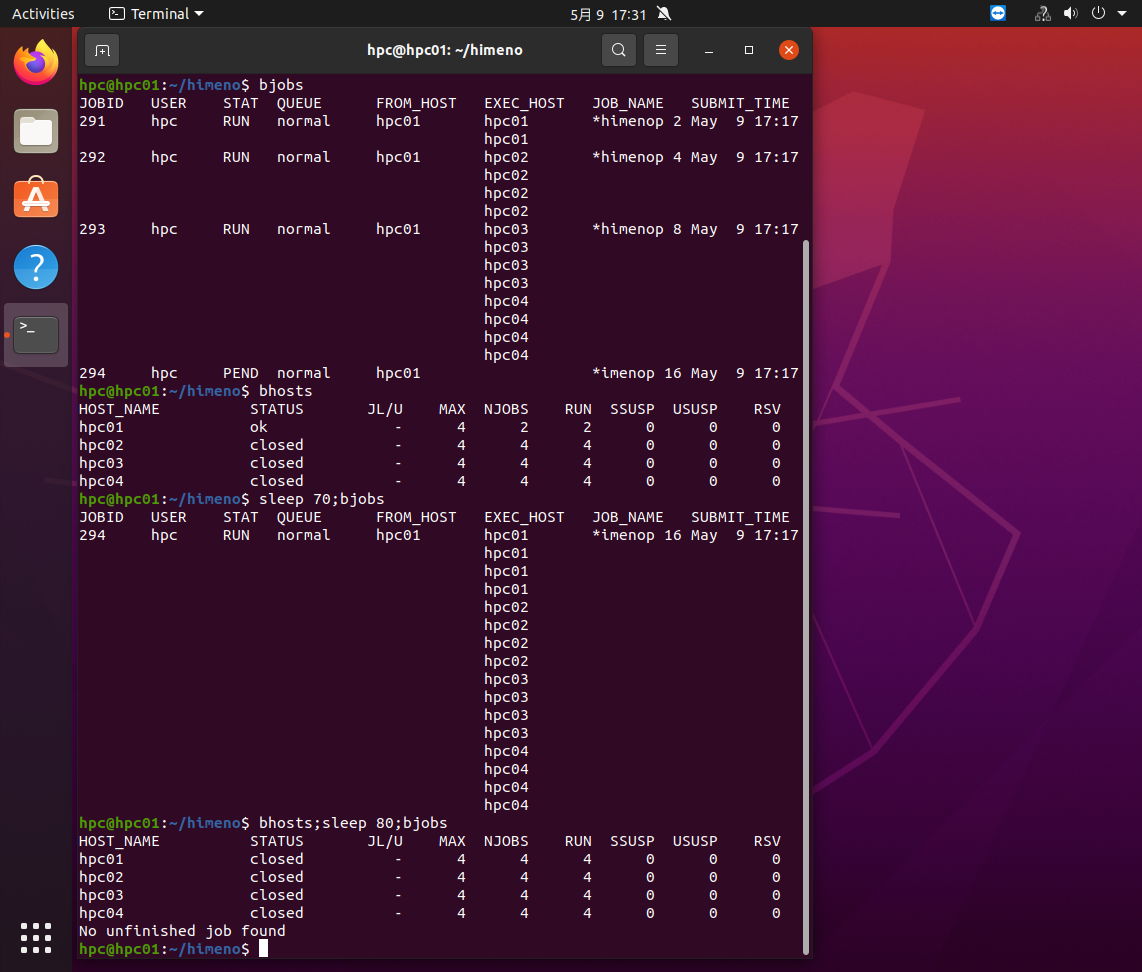
現在流れているジョブはほぼ同時にスタートしていますので、同時に終わります。すると全ノードを使って現在Pendingの16プロセスのジョブが流れ1分ほどするとそれも終了します。
logdirの中に実行結果が書き込まれますが、2プロセスの291.outの最初の25行と最後の20行は下の画面のようになります。
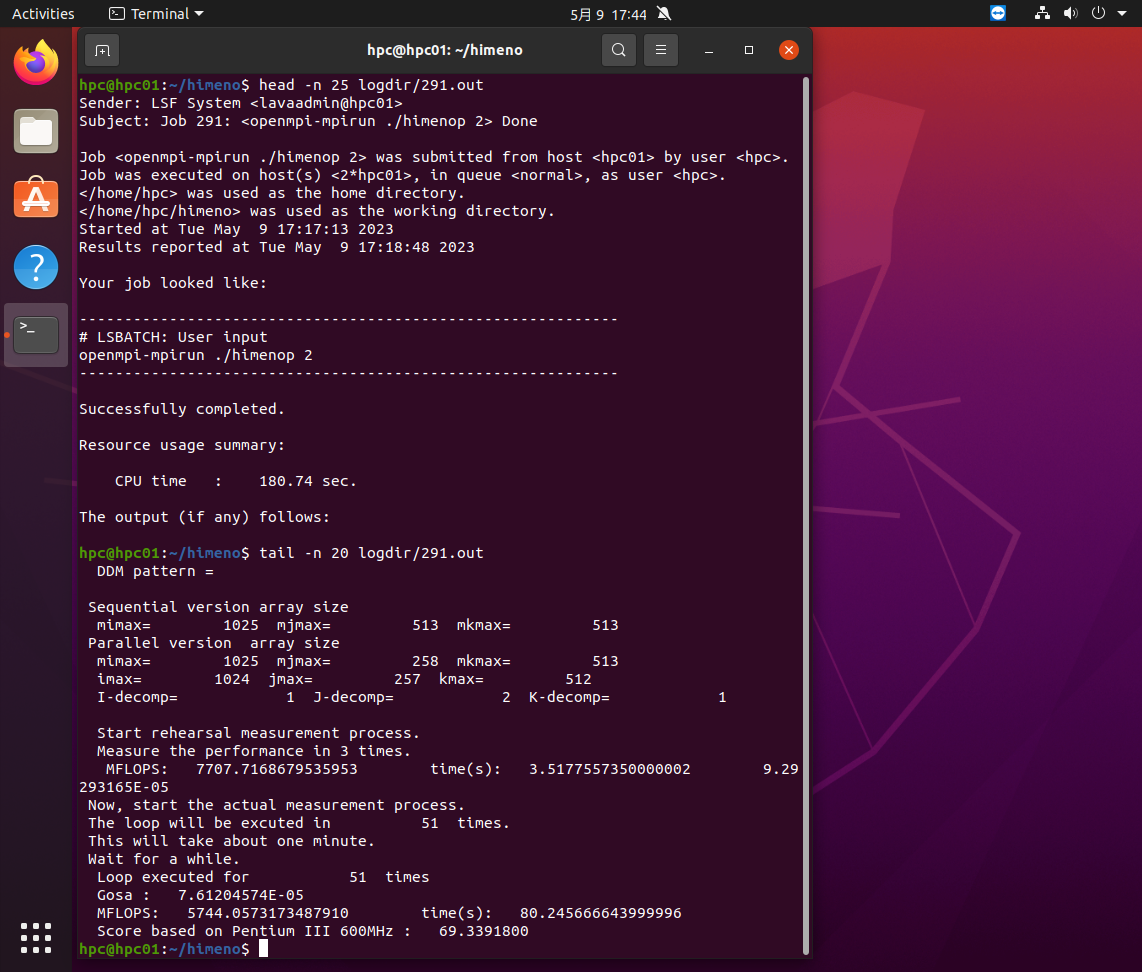
hpc01の2プロセスを使って実行し、5.7MFLOPSの速度だったことがわかります。同様に4プロセスの292.outの最初の25行と最後の20行は下の画面のようになります。
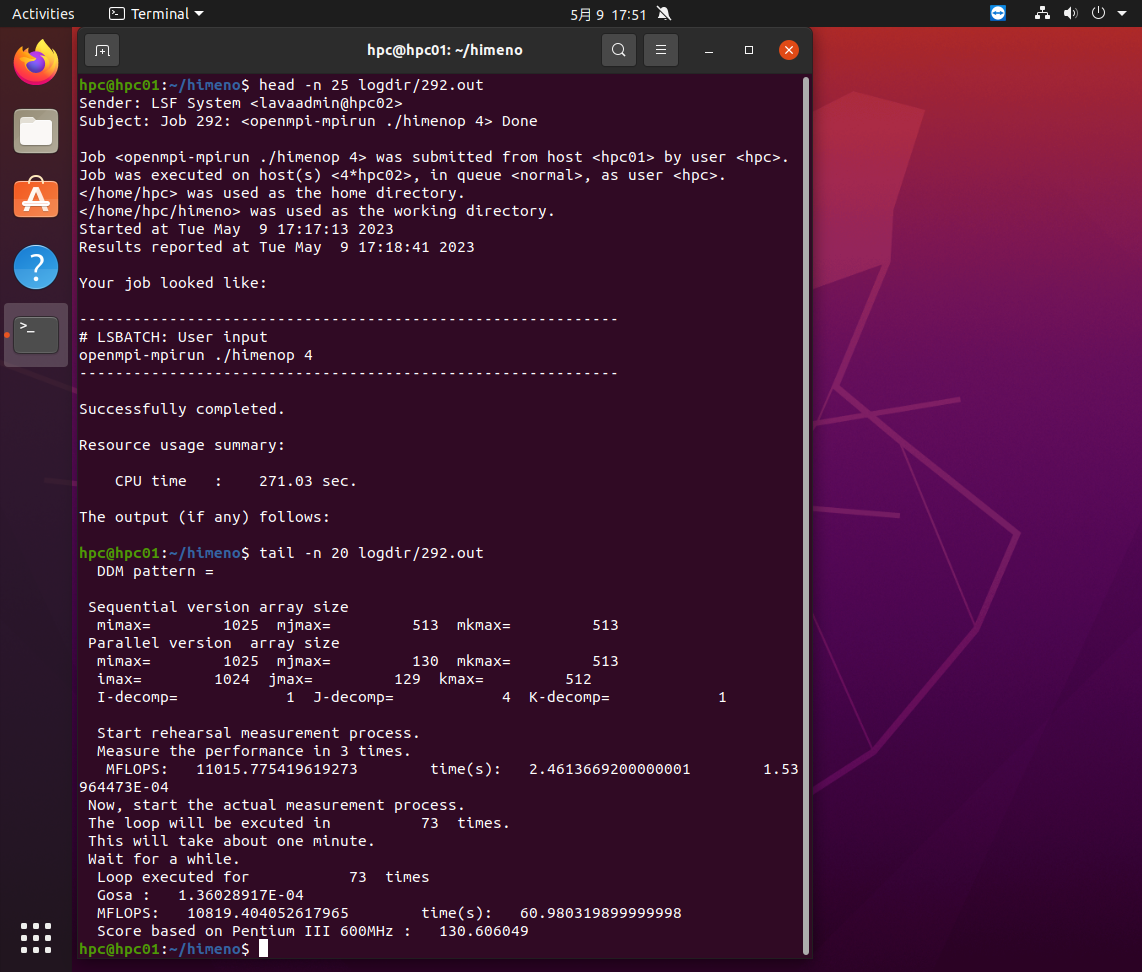
hpc02の4プロセスを使って実行し、10.8MFLOPSの速度だったことがわかります。同様に8プロセスの293.outの最初の25行と最後の20行は下の画面のようになります。
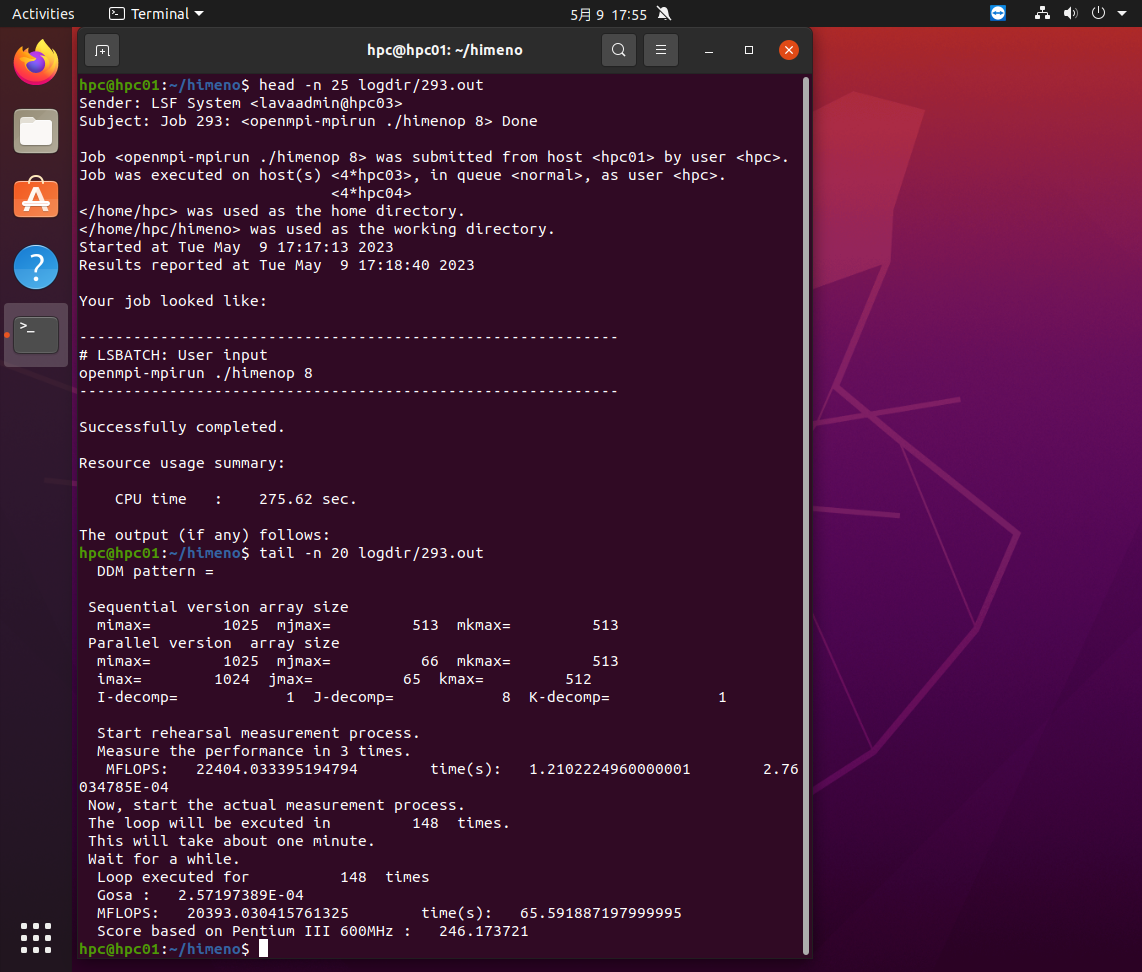
hpc03の4プロセスとhpc04の4プロセス合計8プロセスを使って実行し、20.4MFLOPSの速度だったことがわかります。同様に16プロセスの293.outの最初の25行と最後の20行は下の画面のようになります。
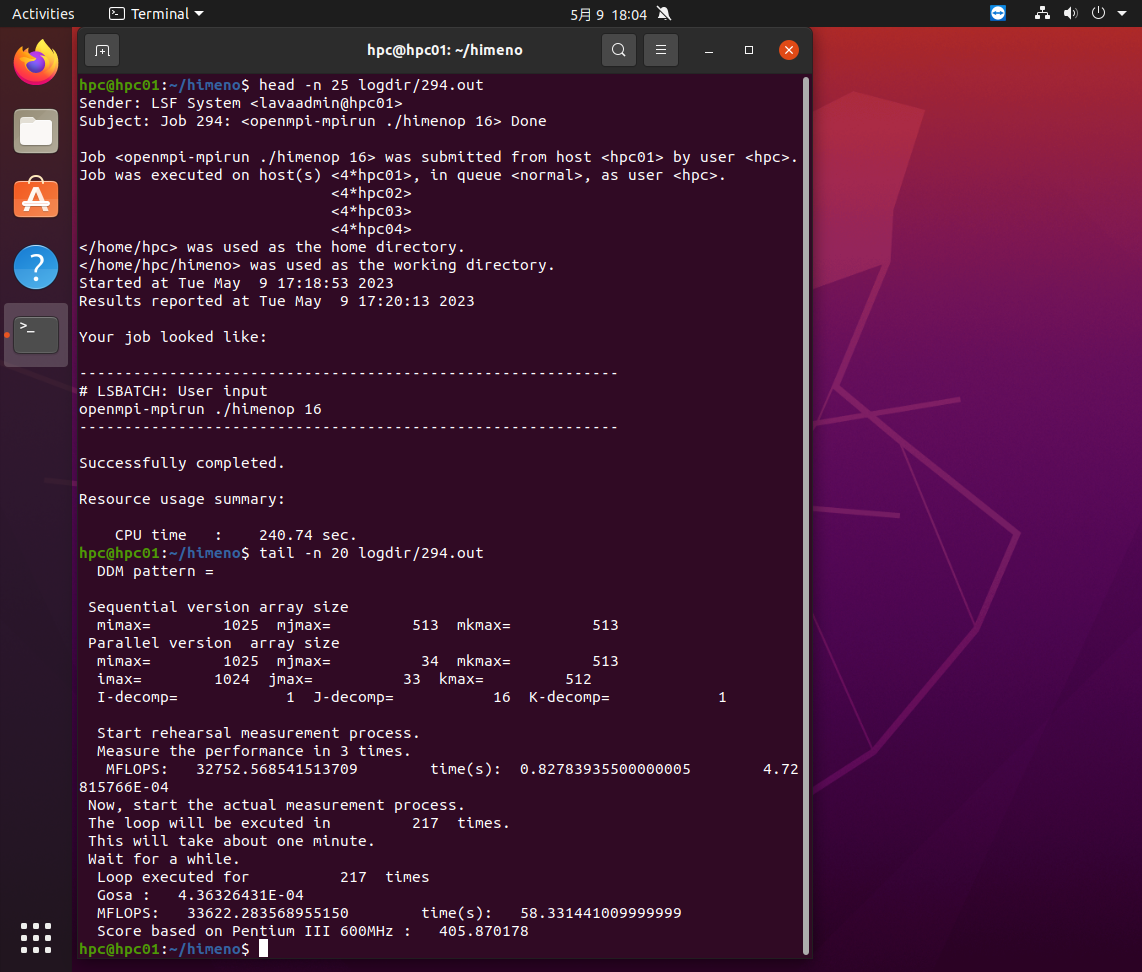
hpc01~hpc04の各4プロセス合計16プロセスを使って実行し、33.6MFLOPSの速度だったことがわかります。以上のようにプロセス数が増えるほど、速度が上がりますが、ノード間の通信速度が遅いと、並列効率が上がらない場合があり、Virtualboxではその傾向があるようです。しかし、機能を試すという目的は十分に達成できました。