SlurmをインストールしてGPU使用のジョブをスケジューリングする
Prod/Rescue + Btrfs/Timeshift のBaseline上で、install/verify/removeのRunbookで安全に試せるようにしています(無償公開)。
以前の記事ではGPUがない場合の、Slurmのインストールと設定と使用方法を解説しましたが、この記事では8GPUのサーバーにSlurmのインストールと設定を行います。設定ファイルの自動生成のスクリプトの紹介も行っていますので、これを使えばGPUサーバーでのSlurmの設定も簡単に行うことができます。その後、tf cnn benchmarksを網羅的にジョブ投入して実行させてみます。OSはubuntu 22.04 LTSです。ubuntu 20.04 LTSとは設定ファイルの場所など微妙に異なりますので、ご注意ください
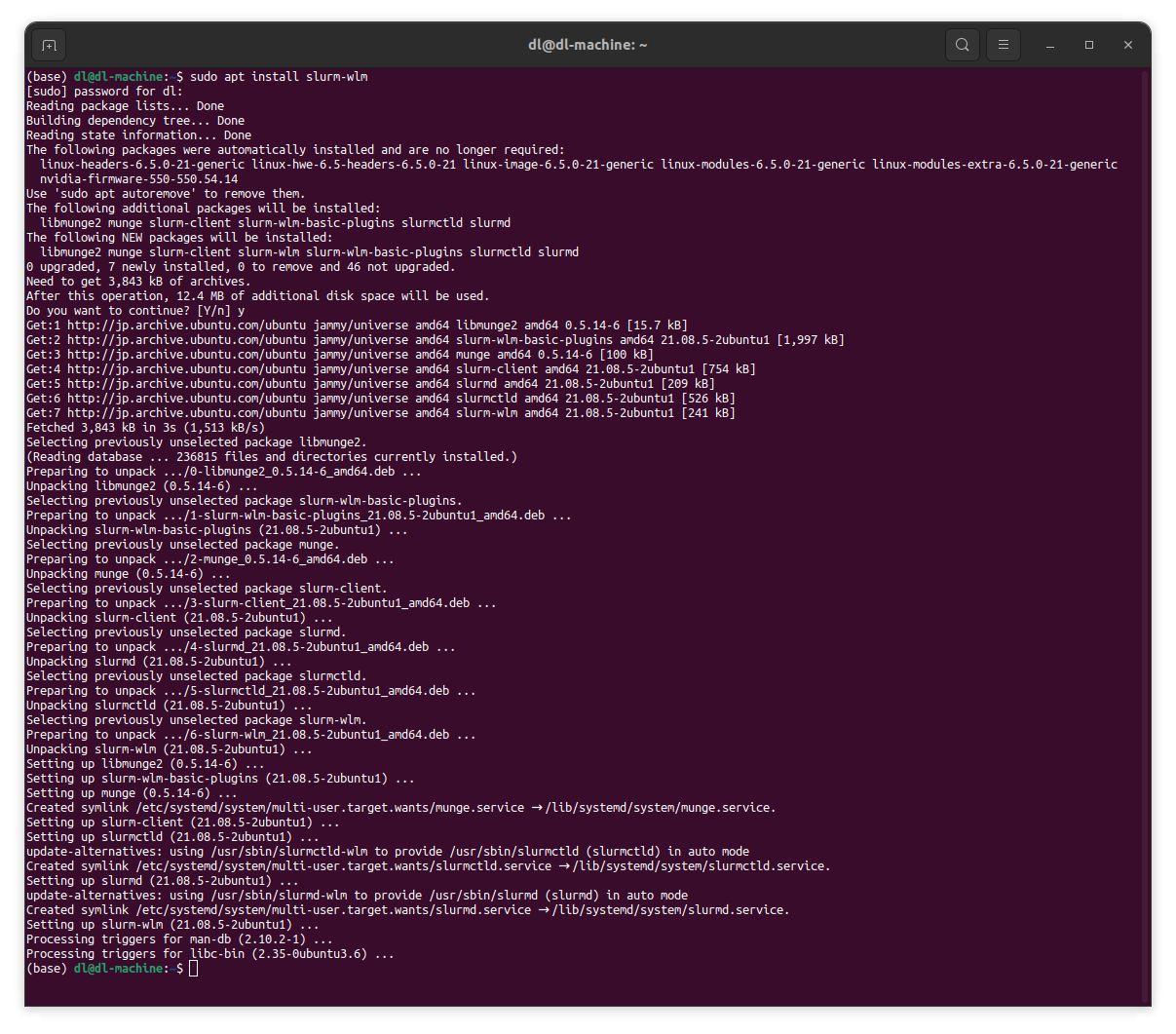
最初に、slurm-wlmパッケージをインストールします。コマンドはsudo apt install slurm-wlmを1行入力するだけですので簡単です。mungeなどの必要なパッケージは全てこのコマンド1つでインストールされます。
この後、/etc/slurm/slurm.confと/etc/slurm/gres.confを用意するのが面倒なのですが、スクリプトを使って使用するサーバーに合わせて自動生成します。それらのスクリプトの紹介も行います。
sudo apt install slurm-wlm
続いて、設定用のファイルslurm.confとgres.confを/etc/slurmの下に用意する必要があるのですが、これらのファイルはパッケージには含まれていません。作成方法がわからない場合、slurm.confは下記のtemplateを使用してください。
このテンプレートを次に紹介するスクリプトで使用中のサーバーまたはワークステーションに合わせた形に自動変更します。以下の内容を/etc/slurm/slurm.confに書き込んでください。slurm-wlmをインストールしただけでは、存在しないファイルです。
/etc/slurm/slurm.conf
# slurm.conf file generated by configurator easy.html.
# Put this file on all nodes of your cluster.
# See the slurm.conf man page for more information.
#
ControlMachine=my-hostname
#ControlAddr=
#
#MailProg=/bin/mail
MpiDefault=none
#MpiParams=ports=#-#
ProctrackType=proctrack/pgid
ReturnToService=1
SlurmctldPidFile=/var/run/slurmctld.pid
#SlurmctldPort=6817
SlurmdPidFile=/var/run/slurmd.pid
#SlurmdPort=6818
SlurmdSpoolDir=/var/spool/slurm/slurmd
#SlurmUser=slurm
SlurmdUser=root
StateSaveLocation=/var/spool/slurm
SwitchType=switch/none
TaskPlugin=task/none
#
GresTypes=gpu
#
#
# TIMERS
#KillWait=30
#MinJobAge=300
#SlurmctldTimeout=120
#SlurmdTimeout=300
#
#
# SCHEDULING
SchedulerType=sched/backfill
SelectType=select/cons_res
SelectTypeParameters=CR_CPU
#
#
# LOGGING AND ACCOUNTING
AccountingStorageType=accounting_storage/none
ClusterName=cluster
#JobAcctGatherFrequency=30
JobAcctGatherType=jobacct_gather/none
#SlurmctldDebug=3
SlurmctldLogFile=/var/log/slurm/slurmctld.log
#SlurmdDebug=3
SlurmdLogFile=/var/log/slurm/slurmd.log
#
#
# COMPUTE NODES
NodeName=my-hostname CPUs=16 RealMemory=515661 Gres=gpu:NVIDIA_GeForce_RTX_4090:8 State=UNKNOWN
PartitionName=debug Nodes=my-hostname Default=YES MaxTime=INFINITE State=UP
このファイルを実際に使用するサーバーに合わせて修正する必要があるのですが、経験がないとどこを修正すればいいのか分かりません。そこで、gpt4に作成させた上記のテンプレートファイルを実機に合わせて修正するupdate_slurm_conf.shを紹介します。
update_slurm_conf.sh
#!/bin/bash
# Get the current hostname
hostname=$(hostname)
# Get CPU cores, sockets, memory, and GPU details
cpu_cores=$(grep -c processor /proc/cpuinfo)
sockets=$(lscpu | grep "Socket(s):" | awk '{print $2}')
cores_per_socket=$((cpu_cores / sockets))
total_memory=$(grep MemTotal /proc/meminfo | awk '{print int($2/1024)}')
# Detect GPU type and count
gpu_type=$(nvidia-smi -L | head -n 1 | \
sed -n 's/.*: \(.*\) (UUID.*/\1/p' | sed 's/ /_/g')
gpu_count=$(nvidia-smi -L | wc -l)
# Backup original slurm.conf
cp /etc/slurm/slurm.conf /etc/slurm/slurm.conf.bak
# Update slurm.conf using awk
awk -v cm="$hostname" -v nn="$hostname" -v cpus="$cpu_cores" \
-v socks="$sockets" -v cps="$cores_per_socket" \
-v mem="$total_memory" -v gres="Gres=gpu:${gpu_type}:${gpu_count}" '
/^ControlMachine=/ {$0="ControlMachine=" cm}
/^NodeName=/ {
$0="NodeName=" nn " CPUs=" cpus " Sockets=" socks \
" CoresPerSocket=" cps " ThreadsPerCore=1 RealMemory=" mem \
" " gres " State=IDLE"
}
/^PartitionName=/ {
$0="PartitionName=main Nodes=" nn " Default=YES MaxTime=INFINITE State=UP"
}
{print}
' /etc/slurm/slurm.conf.bak > /etc/slurm/slurm.conf
echo "Updated slurm.conf successfully with the actual server values."
このスクリプトを実行すると、テンプレートファイルの/etc/slurm/slurm.confは使用中のサーバーまたはワークステーションの構成に合わせて次の様に修正されます。
/etc/slurm/slurm.conf
# slurm.conf file generated by configurator easy.html. # Put this file on all nodes of your cluster. # See the slurm.conf man page for more information. # ControlMachine=dl-machine #ControlAddr= # MpiDefault=none #MpiParams=ports=#-# ProctrackType=proctrack/pgid ReturnToService=1 SlurmctldPidFile=/var/run/slurmctld.pid #SlurmctldPort=6817 SlurmdPidFile=/var/run/slurmd.pid #SlurmdPort=6818 SlurmdSpoolDir=/var/spool/slurm/slurmd #SlurmUser=slurm SlurmdUser=root StateSaveLocation=/var/spool/slurm SwitchType=switch/none TaskPlugin=task/none # GresTypes=gpu # # # TIMERS #KillWait=30 #MinJobAge=300 #SlurmctldTimeout=120 #SlurmdTimeout=300 # # # SCHEDULING SchedulerType=sched/backfill SelectType=select/cons_res SelectTypeParameters=CR_CPU # # # LOGGING AND ACCOUNTING AccountingStorageType=accounting_storage/none ClusterName=cluster #JobAcctGatherFrequency=30 JobAcctGatherType=jobacct_gather/none #SlurmctldDebug=3 SlurmctldLogFile=/var/log/slurm/slurmctld.log #SlurmdDebug=3 SlurmdLogFile=/var/log/slurm/slurmd.log # # # COMPUTE NODES NodeName=dl-machine CPUs=64 Sockets=2 CoresPerSocket=32 ThreadsPerCore=1 RealMemory=515662 Gres=gpu:NVIDIA_GeForce_RTX_4090:8 State=IDLE PartitionName=main Nodes=dl-machine Default=YES MaxTime=INFINITE State=UP
下から2行目を見ると、CPUは2ソケットでそれぞれ32Coreで合計64Coreあり、メモリは512GBと実機に合わせて修正されています。
Slurmの設定ファイルには上記の/etc/slurm/slurm.confの他に、/etc/slurm/gres.confも必要です。この中にGPUの種類や数などを書き込みます。このファイルも経験がないと作成が面倒なので、やはりgpt4に作らせたmake_gres_conf.shを紹介します。
make_gres_conf.sh
#!/bin/bash
# gres.conf のバックアップを作成
if [ -f /etc/slurm/gres.conf ]; then
mv /etc/slurm/gres.conf /etc/slurm/gres.conf.bak
fi
# ホスト名を取得
hostname=$(hostname)
# nvidia-smi -L から最初のGPUのタイプを取得
gpu_type=$(nvidia-smi -L | head -n 1 | sed -n 's/.*: \(.*\) (UUID.*/\1/p' | sed 's/ /_/g')
# nvidia-smi topo -m コマンドの出力から最初のヘッダ行を除外して取得
topo_output=$(nvidia-smi topo -m | tail -n +2)
# CPUアフィニティ情報の解析とgres.confフォーマットでの出力
{
echo "$topo_output" | awk -v hostname="$hostname" -v type="$gpu_type" '
BEGIN {
min_gpu_id = 10000 # 十分に大きな値で初期化
max_gpu_id = -1 # 十分に小さな値で初期化
last_affinity = ""
}
/GPU[0-9]+\t/ {
# GPU ID と CPUアフィニティを抽出
gpu_id = substr($1, 4)
cpu_affinity = $(NF-2)
# 同じCPUアフィニティを持つGPUをグループ化
if (cpu_affinity == last_affinity) {
if (gpu_id < min_gpu_id) min_gpu_id = gpu_id
if (gpu_id > max_gpu_id) max_gpu_id = gpu_id
} else {
if (last_affinity != "") {
print "NodeName=" hostname " Name=gpu Type=" type " File=/dev/nvidia[" min_gpu_id "-" max_gpu_id "] COREs=" last_affinity
}
min_gpu_id = gpu_id
max_gpu_id = gpu_id
last_affinity = cpu_affinity
}
}
END {
# 最後のグループを表示
if (last_affinity != "") {
print "NodeName=" hostname " Name=gpu Type=" type " File=/dev/nvidia[" min_gpu_id "-" max_gpu_id "] COREs=" last_affinity
}
}'
} > /etc/slurm/gres.conf
cat /etc/slurm/gres.conf
echo "New gres.conf has been created and old gres.conf has been backed up."
これを実行すると/etc/slurm/gres.confが生成されます。その内容は
/etc/slurm/gres.conf
NodeName=dl-machine Name=gpu Type=NVIDIA_GeForce_RTX_4090 File=/dev/nvidia[0-3] COREs=0-31 NodeName=dl-machine Name=gpu Type=NVIDIA_GeForce_RTX_4090 File=/dev/nvidia[4-7] COREs=32-63
になります。これをみると、NVIDIA GeForce RTX 4090が8枚搭載されていて、そのうち4枚がCore0~31に、残り4枚がCore 32~63に接続されているgres.confが作成されています。
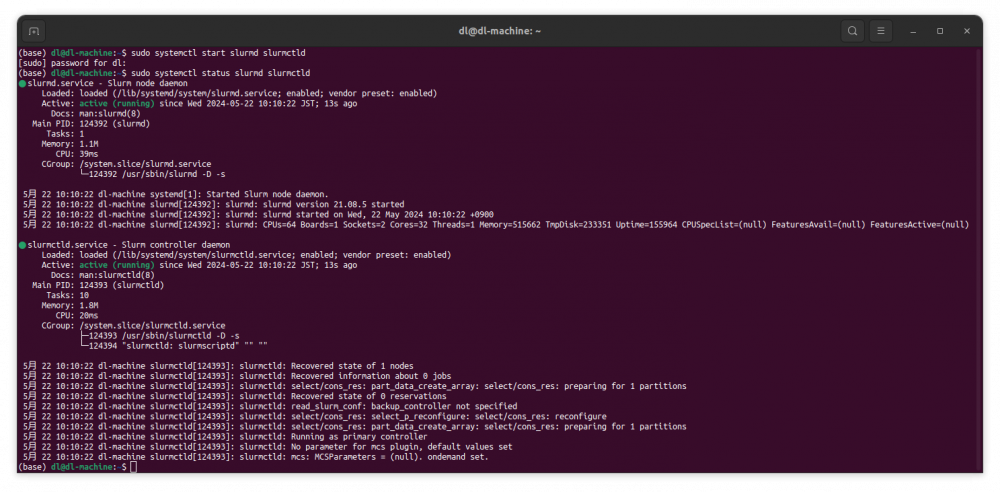
以上でSlurmをインストールして設定に必要なファイルは用意できました。Slurmはslurmd.serviceとslurmctld.serviceの2つで構成されています。ノードが複数ある場合、slurmctld.serviceをジョブ投入するノードで立ち上げ、複数のジョブ実行ノードでslurmd.serviceを立ち上げます。現在は1ノードしかありませんので、slurmd.serviceとslurmctld.serviceを起動します。
起動
sudo systemctl start slurmd slurmctld
確認
sudo systemctl status slurmd slurmctld
sinfoとscontrol show nodesコマンドで、slurmの状態を確認することができます。
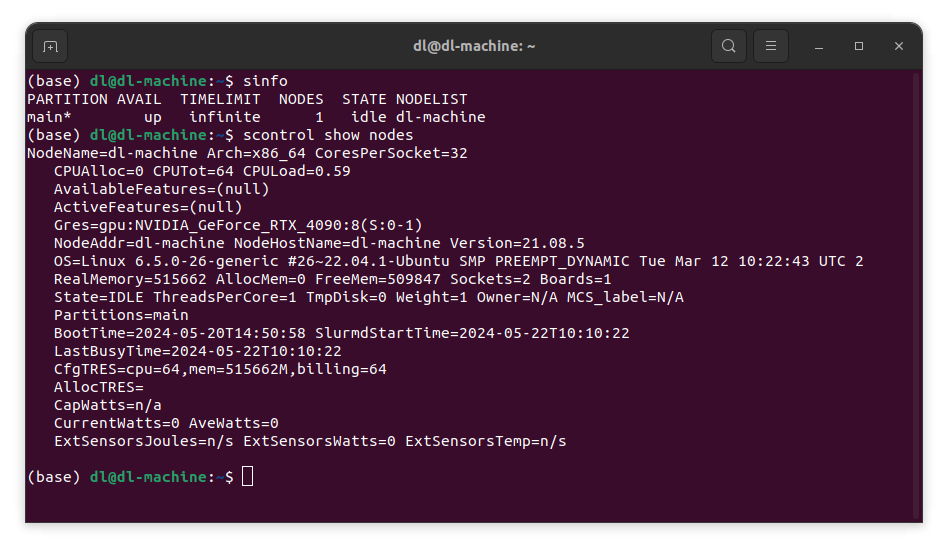
sinfoコマンドでstateがidleと表示されれば、ジョブの投入が可能な状態になっています。もしそうなっていなければ
sudo scontrol update state=idle node=使用中のサーバーのhostname
を入力し、再びsinfoで確認してください。
Slurmのインストールと設定が終わったので、ジョブを投入してみましょう。使用するGPU数を変化させながら、たくさんのジョブを投入する例として、tf cnn benchmarksを使ってみます。すでに/home/dl/tf_cnn_benchmarksにダウロードしてあります。実行するためにはtensorflow1が必要なのでNGCのnvcr.io/nvidia/tensorflow:23.03-tf1-py3を使います。docker用ですがdockerのジョブはSlurmでは流せないので、singularityを使います。
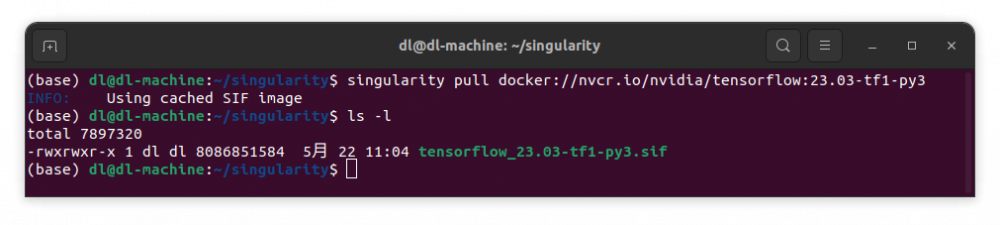
/home/dl/singularityにNGCのnvcr.io/nvidia/tensorflow:23.03-tf1-py3をpullします。
cd /home/dl/singularity
sintularity pull docker://nvcr.io/nvidia/tensorflow:23.03-tf1-py3
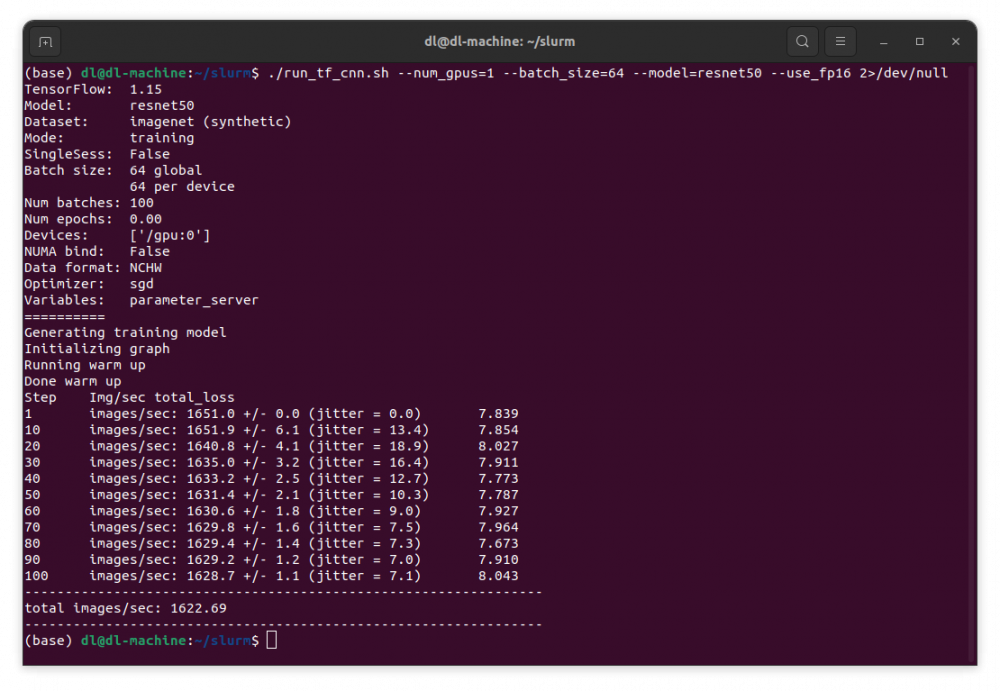
上記でtf_cnn_benchmarksを直接実行するrun_tf_cnn.shを用意しましょう。
run_tf_cnn.sh
#!/bin/bash bench=/home/dl/tf_cnn_benchmarks tf1=/home/dl/singularity/tensorflow_23.03-tf1-py3.sif cd $bench singularity exec --nv $tf1 \ python tf_cnn_benchmarks.py "$@"
これを使って、resnet50を1GPU、batch_size=64、fp16で実行するには ./run_tf_cnn.sh ---num_gpus=1 --batch_size=64 --model=resnet50 --use_fp16を入力します。エラー出力に大量のメッセージが出ますので、それをなくして結果のみを表示するには2>/dev/nullを最後に付けます。
直接実行ではなく、Slurmのジョブとして投入するsjob_tf_cnn.shを用意します。
#!/bin/bash
args="$@"
# Parse command line arguments
OPTIONS=$(getopt -o b:m:n:e:f --long batch_size:,model:,num_gpus:,num_epochs:,use_fp16 -- "$@")
if [ $? != 0 ]; then
echo "Error in command line parsing" >&2
exit 1
fi
# Set the parsed options into the positional parameters
eval set -- "$OPTIONS"
# Initialize default values
num_gpus=1
batch_size=32
model="default_model"
use_fp16="" # Default to not using FP16
# Extract options and their arguments into variables.
while true; do
case "$1" in
--num_gpus )
num_gpus="$2"
shift 2
;;
--batch_size )
batch_size="$2"
shift 2
;;
--model )
model="$2"
shift 2
;;
--use_fp16 )
use_fp16=fp16
shift
;;
-- )
shift
break
;;
* )
break
;;
esac
done
logdir=logdir
errdir=errdir
jobname="${model}_gpus${num_gpus}_bs${batch_size}_${use_fp16}"
mkdir -p ${logdir} ${errdir}
sbatch -J $jobname <<...
#!/bin/bash
#SBATCH --gres=gpu:$num_gpus
#SBATCH -o ${logdir}/$jobname.log
#SBATCH -e ${errdir}/$jobname.err
./run_tf_cnn.sh $args
...こ
このscriptを使用してresnet50を1gpuでbatch_size=64, use_fp16でジョブ投入するには
./sjob_tf_cnn.sh --model=resnet50 --num_gpus=1 --batch_size=64 --use_fp16
を入力します。
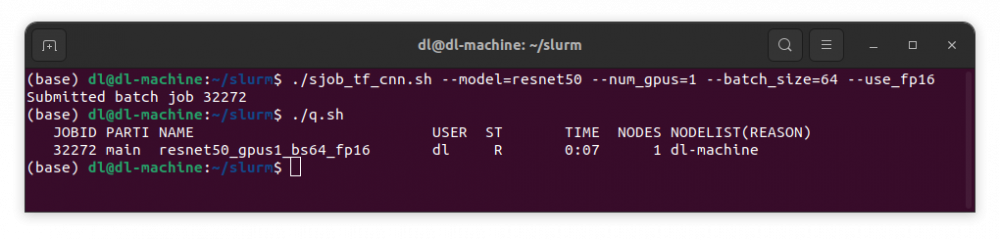
少しすると実行が終わり結果がlogdirの下に書き込まれます。
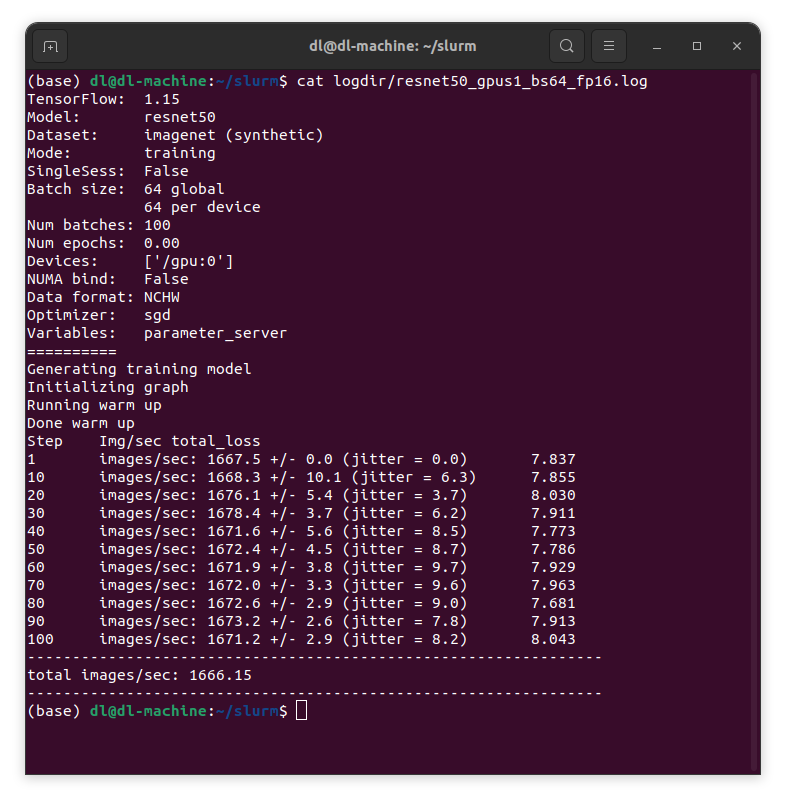
それではこのスクリプトを使って、modelをresnet50, inception3, nasnet, resnet152, inception4のそれぞれ、gpu数は1, 2, 4, 8と変化させ、fp16とfp32で、バッチサイズはfp16の時64, 128, 256, 512と変化させ、fp32では64, 128, 256と変化させてジョブ投入してみます。そのスクリプトall_tf_cnn.shは
all_tf_cnn.sh
#!/bin/bash for gpu in 1 2 4 8; do for model in resnet50 inception3 nasnet resnet152 inception4;do for bs in 64 128 256 512; do ./sjob_tf_cnn.sh --model=$model --num_gpus=$gpu --batch_size=$bs --use_fp16 done for bs in 64 128 256 ; do ./sjob_tf_cnn.sh --model=$model --num_gpus=$gpu --batch_size=$bs done done done
これを実行してジョブキューを見ると、1GPUのジョブが8個同時に実行されているのがわかります。
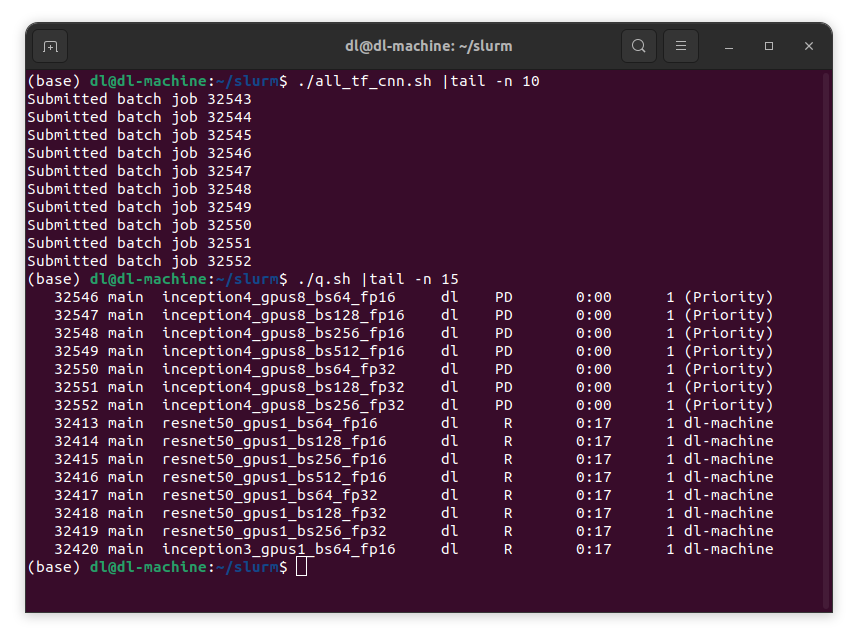
全部のジョブが終わるまで少し時間がかかりますが、結果はlogdirに書き込まれていきます。fp16の全結果は
(base) dl@dl-machine:~/slurm$ grep "total images" logdir/*|grep fp16 logdir/inception3_gpus1_bs064_fp16.log:total images/sec: 1218.21 logdir/inception3_gpus1_bs128_fp16.log:total images/sec: 1353.79 logdir/inception3_gpus1_bs256_fp16.log:total images/sec: 1384.33 logdir/inception3_gpus2_bs064_fp16.log:total images/sec: 1747.86 logdir/inception3_gpus2_bs128_fp16.log:total images/sec: 2443.61 logdir/inception3_gpus2_bs256_fp16.log:total images/sec: 2485.44 logdir/inception3_gpus4_bs064_fp16.log:total images/sec: 2629.04 logdir/inception3_gpus4_bs128_fp16.log:total images/sec: 3892.85 logdir/inception3_gpus4_bs256_fp16.log:total images/sec: 4859.83 logdir/inception3_gpus8_bs064_fp16.log:total images/sec: 4080.31 logdir/inception3_gpus8_bs128_fp16.log:total images/sec: 7323.04 logdir/inception3_gpus8_bs256_fp16.log:total images/sec: 8714.23 logdir/inception4_gpus1_bs064_fp16.log:total images/sec: 652.21 logdir/inception4_gpus1_bs128_fp16.log:total images/sec: 705.07 logdir/inception4_gpus1_bs256_fp16.log:total images/sec: 728.66 logdir/inception4_gpus2_bs064_fp16.log:total images/sec: 1171.17 logdir/inception4_gpus2_bs128_fp16.log:total images/sec: 1293.60 logdir/inception4_gpus2_bs256_fp16.log:total images/sec: 1414.80 logdir/inception4_gpus4_bs064_fp16.log:total images/sec: 1654.92 logdir/inception4_gpus4_bs128_fp16.log:total images/sec: 2355.98 logdir/inception4_gpus4_bs256_fp16.log:total images/sec: 2565.25 logdir/inception4_gpus8_bs064_fp16.log:total images/sec: 3005.81 logdir/inception4_gpus8_bs128_fp16.log:total images/sec: 3715.53 logdir/inception4_gpus8_bs256_fp16.log:total images/sec: 4675.25 logdir/nasnet_gpus1_bs064_fp16.log:total images/sec: 578.94 logdir/nasnet_gpus1_bs128_fp16.log:total images/sec: 822.82 logdir/nasnet_gpus1_bs256_fp16.log:total images/sec: 850.15 logdir/nasnet_gpus2_bs064_fp16.log:total images/sec: 690.13 logdir/nasnet_gpus2_bs128_fp16.log:total images/sec: 1156.35 logdir/nasnet_gpus2_bs256_fp16.log:total images/sec: 1495.46 logdir/nasnet_gpus4_bs064_fp16.log:total images/sec: 1192.13 logdir/nasnet_gpus4_bs128_fp16.log:total images/sec: 2028.21 logdir/nasnet_gpus4_bs256_fp16.log:total images/sec: 2597.26 logdir/nasnet_gpus8_bs064_fp16.log:total images/sec: 1320.31 logdir/nasnet_gpus8_bs128_fp16.log:total images/sec: 2454.55 logdir/nasnet_gpus8_bs256_fp16.log:total images/sec: 4056.95 logdir/resnet152_gpus1_bs064_fp16.log:total images/sec: 743.77 logdir/resnet152_gpus1_bs128_fp16.log:total images/sec: 761.17 logdir/resnet152_gpus1_bs256_fp16.log:total images/sec: 776.55 logdir/resnet152_gpus2_bs064_fp16.log:total images/sec: 1168.04 logdir/resnet152_gpus2_bs128_fp16.log:total images/sec: 1337.09 logdir/resnet152_gpus2_bs256_fp16.log:total images/sec: 1271.09 logdir/resnet152_gpus4_bs064_fp16.log:total images/sec: 1439.98 logdir/resnet152_gpus4_bs128_fp16.log:total images/sec: 2362.94 logdir/resnet152_gpus4_bs256_fp16.log:total images/sec: 2735.54 logdir/resnet152_gpus8_bs064_fp16.log:total images/sec: 1871.35 logdir/resnet152_gpus8_bs128_fp16.log:total images/sec: 3474.90 logdir/resnet152_gpus8_bs256_fp16.log:total images/sec: 4435.13 logdir/resnet50_gpus1_bs064_fp16.log:total images/sec: 1698.54 logdir/resnet50_gpus1_bs128_fp16.log:total images/sec: 1727.71 logdir/resnet50_gpus1_bs256_fp16.log:total images/sec: 1757.55 logdir/resnet50_gpus1_bs512_fp16.log:total images/sec: 1687.52 logdir/resnet50_gpus1_bs64_fp16.log:total images/sec: 1666.15 logdir/resnet50_gpus2_bs064_fp16.log:total images/sec: 2960.08 logdir/resnet50_gpus2_bs128_fp16.log:total images/sec: 3229.78 logdir/resnet50_gpus2_bs256_fp16.log:total images/sec: 3389.79 logdir/resnet50_gpus2_bs512_fp16.log:total images/sec: 3449.47 logdir/resnet50_gpus4_bs064_fp16.log:total images/sec: 3268.76 logdir/resnet50_gpus4_bs128_fp16.log:total images/sec: 5132.59 logdir/resnet50_gpus4_bs256_fp16.log:total images/sec: 5960.33 logdir/resnet50_gpus4_bs512_fp16.log:total images/sec: 6407.52 logdir/resnet50_gpus8_bs064_fp16.log:total images/sec: 6193.34 logdir/resnet50_gpus8_bs128_fp16.log:total images/sec: 8740.77 logdir/resnet50_gpus8_bs256_fp16.log:total images/sec: 10449.17 logdir/resnet50_gpus8_bs512_fp16.log:total images/sec: 12024.88 (base) dl@dl-machine:~/slurm$
fp32の全結果は
(base) dl@dl-machine:~/slurm$ grep "total images" logdir/*|grep fp32 logdir/inception3_gpus1_bs064_fp32.log:total images/sec: 635.66 logdir/inception3_gpus1_bs128_fp32.log:total images/sec: 633.71 logdir/inception3_gpus2_bs064_fp32.log:total images/sec: 1132.84 logdir/inception3_gpus2_bs128_fp32.log:total images/sec: 1141.17 logdir/inception3_gpus4_bs064_fp32.log:total images/sec: 1835.34 logdir/inception3_gpus4_bs128_fp32.log:total images/sec: 2154.26 logdir/inception3_gpus8_bs064_fp32.log:total images/sec: 2964.47 logdir/inception3_gpus8_bs128_fp32.log:total images/sec: 3751.83 logdir/inception4_gpus1_bs064_fp32.log:total images/sec: 330.95 logdir/inception4_gpus1_bs128_fp32.log:total images/sec: 331.15 logdir/inception4_gpus2_bs064_fp32.log:total images/sec: 623.09 logdir/inception4_gpus2_bs128_fp32.log:total images/sec: 622.94 logdir/inception4_gpus4_bs064_fp32.log:total images/sec: 1103.05 logdir/inception4_gpus4_bs128_fp32.log:total images/sec: 1187.28 logdir/inception4_gpus8_bs064_fp32.log:total images/sec: 1669.53 logdir/inception4_gpus8_bs128_fp32.log:total images/sec: 2057.18 logdir/nasnet_gpus1_bs064_fp32.log:total images/sec: 633.57 logdir/nasnet_gpus1_bs128_fp32.log:total images/sec: 731.36 logdir/nasnet_gpus1_bs256_fp32.log:total images/sec: 732.61 logdir/nasnet_gpus2_bs064_fp32.log:total images/sec: 641.34 logdir/nasnet_gpus2_bs128_fp32.log:total images/sec: 1146.73 logdir/nasnet_gpus2_bs256_fp32.log:total images/sec: 1315.37 logdir/nasnet_gpus4_bs064_fp32.log:total images/sec: 934.49 logdir/nasnet_gpus4_bs128_fp32.log:total images/sec: 1877.79 logdir/nasnet_gpus4_bs256_fp32.log:total images/sec: 2347.97 logdir/nasnet_gpus8_bs064_fp32.log:total images/sec: 1344.31 logdir/nasnet_gpus8_bs128_fp32.log:total images/sec: 2447.38 logdir/nasnet_gpus8_bs256_fp32.log:total images/sec: 3680.45 logdir/resnet152_gpus1_bs064_fp32.log:total images/sec: 359.76 logdir/resnet152_gpus1_bs128_fp32.log:total images/sec: 367.39 logdir/resnet152_gpus2_bs064_fp32.log:total images/sec: 640.16 logdir/resnet152_gpus2_bs128_fp32.log:total images/sec: 680.48 logdir/resnet152_gpus4_bs064_fp32.log:total images/sec: 1043.20 logdir/resnet152_gpus4_bs128_fp32.log:total images/sec: 1221.18 logdir/resnet152_gpus8_bs064_fp32.log:total images/sec: 1662.98 logdir/resnet152_gpus8_bs128_fp32.log:total images/sec: 2020.20 logdir/resnet50_gpus1_bs064_fp32.log:total images/sec: 814.53 logdir/resnet50_gpus1_bs128_fp32.log:total images/sec: 827.80 logdir/resnet50_gpus1_bs256_fp32.log:total images/sec: 828.94 logdir/resnet50_gpus2_bs064_fp32.log:total images/sec: 1509.93 logdir/resnet50_gpus2_bs128_fp32.log:total images/sec: 1592.91 logdir/resnet50_gpus2_bs256_fp32.log:total images/sec: 1620.19 logdir/resnet50_gpus4_bs064_fp32.log:total images/sec: 2512.52 logdir/resnet50_gpus4_bs128_fp32.log:total images/sec: 2798.14 logdir/resnet50_gpus4_bs256_fp32.log:total images/sec: 3080.66 logdir/resnet50_gpus8_bs064_fp32.log:total images/sec: 3843.12 logdir/resnet50_gpus8_bs128_fp32.log:total images/sec: 4857.48 logdir/resnet50_gpus8_bs256_fp32.log:total images/sec: 5672.22 (base) dl@dl-machine:~/slurm$
となりました。



-
 HPCDIY-SRXGPU8R4S Computer
HPCDIY-SRXGPU8R4S ComputerFrom ¥5,795,383.00 ¥5,268,530.00
To ¥26,384,501.00 ¥23,985,910.00